
आर्टिफिशियल इंटेलिजेंस (AI) की दुनिया में दो टर्म्स अक्सर सुनने को मिलते हैं: मशीन लर्निंग (ML) और डीप लर्निंग (DL)। ये दोनों ही AI के अहम हिस्से हैं, लेकिन इनमें कई मौलिक अंतर हैं। अगर आप एक स्टूडेंट, टेक एन्थूजियास्ट, या प्रोफेशनल हैं, तो इन दोनों के बीच के डिफरेंसेस को समझना जरूरी है। इस आर्टिकल में हम ML और DL की परिभाषाओं, टेक्निकल विशेषताओं, रियल-लाइफ एप्लीकेशंस, और इनके बीच के की डिफरेंसेस को विस्तार से समझेंगे।
Table of Contents
Toggleमशीन लर्निंग (ML) क्या है?
मशीन लर्निंग, AI का एक सबसेट है जो सिस्टम्स को ऑटोमेटिकली लर्न करने और एक्सपीरियंस से इम्प्रूव करने की कैपेबिलिटी प्रदान करता है। ML एल्गोरिथम्स डेटा पैटर्न्स को पहचानते हैं और उसके आधार पर प्रेडिक्शन्स या डिसीजन्स लेते हैं। यहां तक कि बिना एक्सप्लिसिटली प्रोग्राम्ड किए हुए भी!
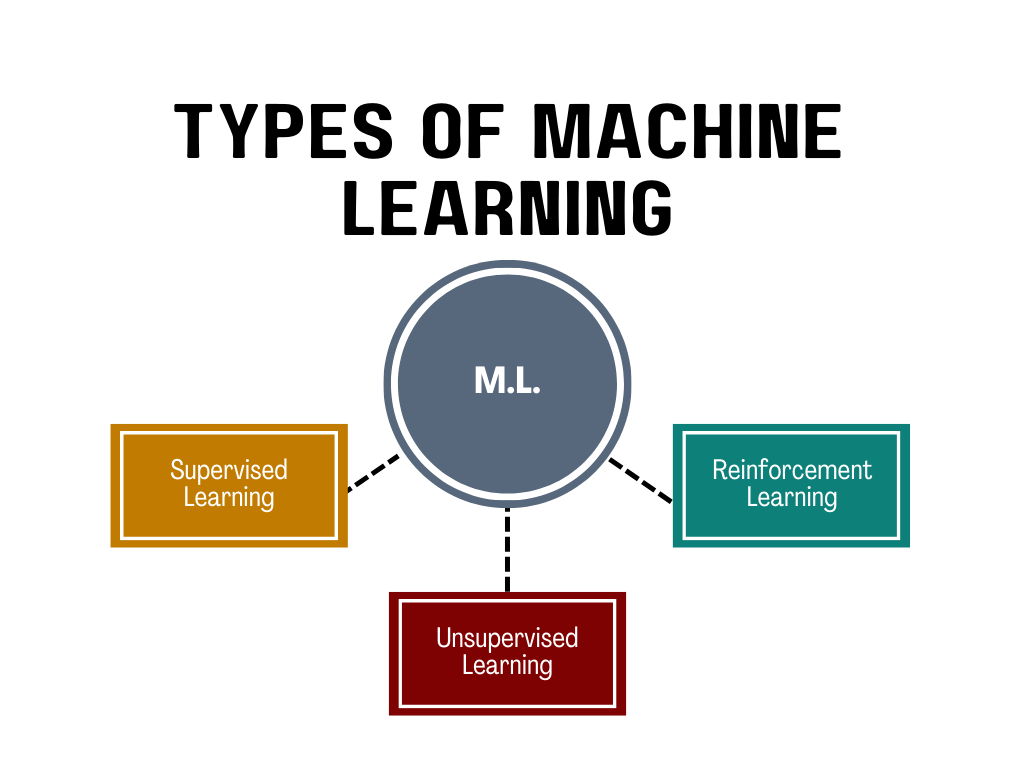
ML के प्रमुख प्रकार:
- सुपरवाइज्ड लर्निंग (Supervised Learning) : इसमें मॉडल को लेबलड डेटा (इनपुट-आउटपुट पेयर्स) के साथ ट्रेन किया जाता है।
उदाहरण: स्पैम डिटेक्शन, वेदर प्रेडिक्शन।
- अनसुपरवाइज्ड लर्निंग (Unsupervised Learning) : इसमें मॉडल अनलेबलड डेटा से पैटर्न्स खोजता है।
उदाहरण: कस्टमर सेगमेंटेशन, एनोमली डिटेक्शन।
- रीइन्फोर्समेंट लर्निंग (Reinforcement Learning) : यहां मॉडल एक एनवायरनमेंट में एक्शन्स लेकर रिवार्ड्स मैक्सिमाइज करना सीखता है।
उदाहरण: गेम AI (जैसे AlphaGo), रोबोटिक्स।
ML की विशेषताएँ:
- फीचर इंजीनियरिंग की आवश्यकता: डेटा साइंटिस्ट्स को मैनुअली रेलेवेंट फीचर्स एक्सट्रैक्ट करने पड़ते हैं।
- मॉडरेट डेटा डिपेंडेंसी: अच्छी एक्यूरेसी के लिए स्ट्रक्चर्ड डेटा और मीडियम-साइज़्ड डेटासेट्स चाहिए।
- इंटरप्रेटेबिलिटी: ML मॉडल्स (जैसे डिसीजन ट्रीज़, लीनियर रिग्रेशन) के रिजल्ट्स को समझना आसान होता है।
डीप लर्निंग (DL) क्या है?
डीप लर्निंग, मशीन लर्निंग का ही एक एडवांस्ड सबसेट है, जो आर्टिफिशियल न्यूरल नेटवर्क्स (ANNs) पर आधारित है। DL मॉडल्स, ह्यूमन ब्रेन की तरह लेयर्ड न्यूरॉन्स के नेटवर्क का उपयोग करते हैं, जिन्हें डीप न्यूरल नेटवर्क्स कहा जाता है। ये मॉडल्स रॉ डेटा से ऑटोमेटिकली हाई-लेवल फीचर्स एक्सट्रैक्ट करना सीखते हैं, इसलिए इन्हें “एंड-टू-एंड लर्निंग” भी कहते हैं।
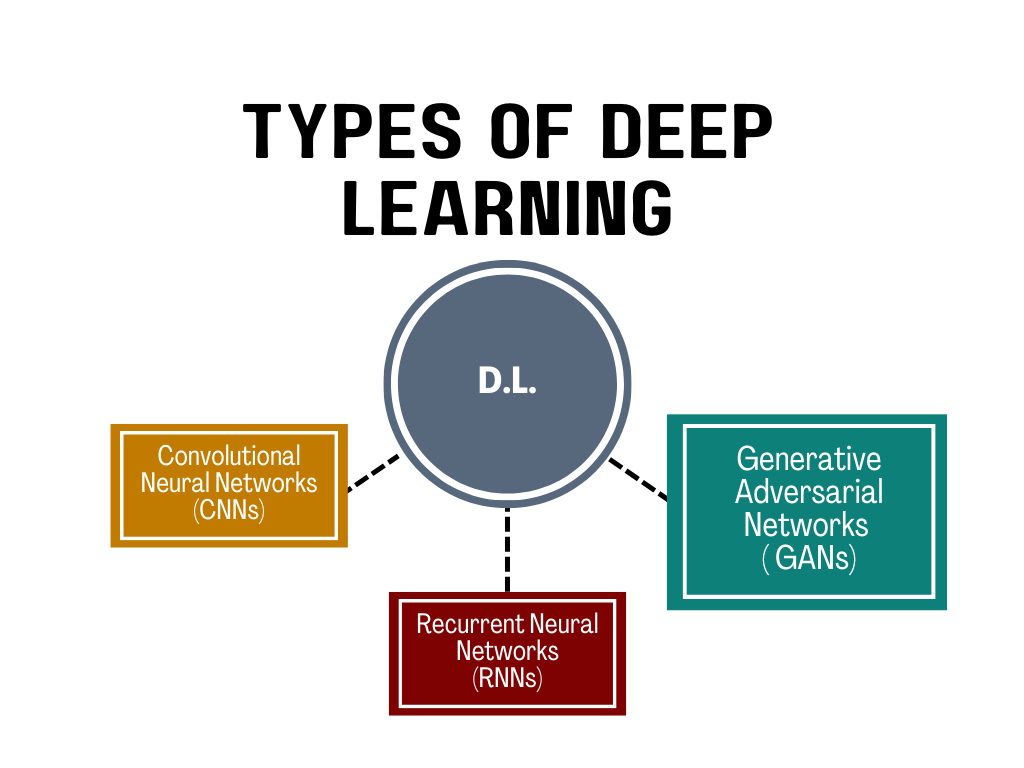
DL के प्रमुख प्रकार:
- कन्वोल्यूशनल न्यूरल नेटवर्क्स (CNNs): इमेज और वीडियो प्रोसेसिंग के लिए उपयोगी।
- रिकरेंट न्यूरल नेटवर्क्स (RNNs): सीक्वेंशियल डेटा (जैसे टेक्स्ट, टाइम सीरीज़) के लिए इस्तेमाल होते हैं।
- जेनेरेटिव एडवर्सैरियल नेटवर्क्स (GANs): रियलिस्टिक इमेजेस या डेटा जनरेट करने के लिए।
DL की विशेषताएँ:
- ऑटोमेटिक फीचर एक्सट्रैक्शन: रॉ डेटा से स्वयं फीचर्स लर्न करता है, मैनुअल इंटरवेंशन कम।
- हाई डेटा डिपेंडेंसी: बेहतर परफॉर्मेंस के लिए मैसिव डेटासेट्स (जैसे लाखों इमेजेस) चाहिए।
- कम्प्यूटेशनल इंटेंसिटी: GPUs या TPUs जैसे हाई-परफॉर्मेंस हार्डवेयर की आवश्यकता।
- ब्लैक बॉक्स नेचर: मॉडल्स के निर्णयों को समझना कॉम्प्लेक्स होता है।
मशीन लर्निंग (ML) और डीप लर्निंग (DL) में मुख्य अंतर
1. डेटा डिपेंडेंसी
- ML: मीडियम-साइज़्ड डेटासेट्स (कुछ हज़ार सैंपल्स) पर अच्छा परफॉर्म करता है।
- DL: मैसिव डेटासेट्स (लाखों सैंपल्स) की डिमांड, छोटे डेटासेट्स पर ओवरफिट हो सकता है।
उदाहरण:
- अगर आपके पास 10,000 प्रोडक्ट रिव्यूज हैं, तो ML एल्गोरिथम्स (जैसे SVM, रैंडम फॉरेस्ट) सेंटीमेंट एनालिसिस के लिए पर्याप्त हैं।
- वहीं, DL मॉडल (जैसे BERT) को ट्रेन करने के लिए लाखों टेक्स्ट सैंपल्स चाहिए, लेकिन यह न्यूएंसड इमोशंस को भी पकड़ सकता है।
2. फीचर इंजीनियरिंग
- ML: डेटा साइंटिस्ट्स को मैनुअली फीचर्स (जैसे इमेज में एजेस, टेक्स्ट में कीवर्ड्स) सेलेक्ट करने होते हैं।
- DL: मॉडल स्वयं लेयर्स के थ्रू हायरार्किकल फीचर्स सीखता है।
उदाहरण:
- एक ML मॉडल में फेस रिकॉग्निशन के लिए हमें आइज़, नोज, माउथ जैसे फीचर्स मैनुअली आइडेंटिफाई करने होंगे।
- DL मॉडल (जैसे CNN) रॉ पिक्सल्स से एजेस → टेक्सचर्स → फेशियल पार्ट्स → एंटायर फेस सीखता है।
3. कम्प्यूटेशनल रिसोर्सेज
- ML: CPUs पर भी चल सकता है, ट्रेनिंग टाइम कम।
- DL: GPUs/TPUs की जरूरत, ट्रेनिंग में घंटों से लेकर हफ़्तों तक लग सकते हैं।
उदाहरण:
- Scikit-learn का लॉजिस्टिक रिग्रेशन मॉडल एक लैपटॉप पर कुछ मिनटों में ट्रेन हो जाता है।
- DL-बेस्ड GPT-4 जैसे मॉडल्स को ट्रेन करने के लिए हज़ारों GPUs और महीनों का समय लगता है।
4. इंटरप्रेटेबिलिटी
- ML: ट्रांसपेरेंट मॉडल्स (जैसे डिसीजन ट्रीज़) के निर्णयों को आसानी से समझा जा सकता है।
- DL: मॉडल्स की कॉम्प्लेक्सिटी के कारण यह पता लगाना मुश्किल होता है कि निर्णय कैसे हुआ।
उदाहरण:
- एक बैंक लोन अप्रूवल सिस्टम में ML मॉडल बता सकता है कि “आवेदक की इनकम 50,000 से कम है, इसलिए लोन रिजेक्ट”।
- DL मॉडल यही निर्णय लेगा, लेकिन एग्जैक्ट रीज़न बताने में असमर्थ रहेगा।
5. एप्लीकेशन स्कोप
- ML: स्ट्रक्चर्ड डेटा (टेबल्स, स्प्रेडशीट्स) और मीडियम-कॉम्प्लेक्सिटी टास्क के लिए उपयुक्त।
- DL: अनस्ट्रक्चर्ड डेटा (इमेजेस, ऑडियो, टेक्स्ट) और हाईली कॉम्प्लेक्स टास्क (जैसे ऑटोनॉमस ड्राइविंग) में बेहतर।
उदाहरण:
- ML: Netflix की रेकमेंडेशन सिस्टम (यूजर रेटिंग्स और वॉच हिस्ट्री के आधार पर)।
- DL: Tesla की सेल्फ-ड्राइविंग कार्स, जो रियल-टाइम में कैमराज़ और सेंसर्स के डेटा को प्रोसेस करती हैं।
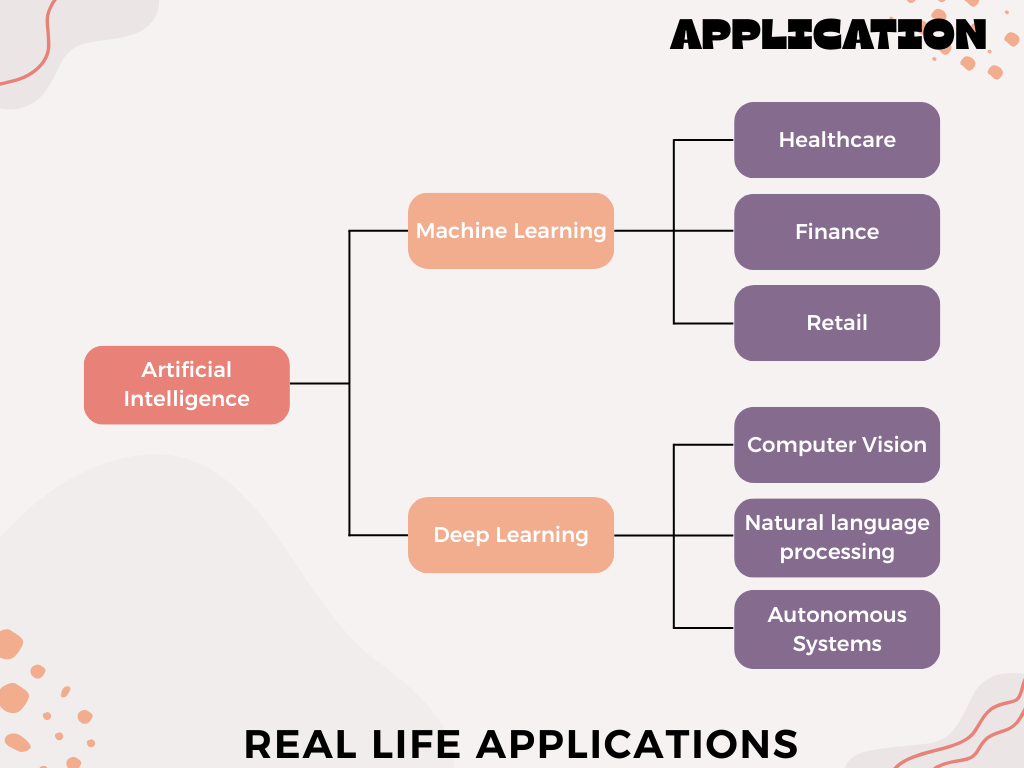
रियल-लाइफ एप्लीकेशंस: ML vs DL
मशीन लर्निंग के उदाहरण:
- हेल्थकेयर: डिसीज़ प्रेडिक्शन (डायबिटीज, हृदय रोग) पेशेंट हिस्ट्री और लैब रिपोर्ट्स के आधार पर।
- फाइनेंस: फ्रॉड डिटेक्शन, क्रेडिट स्कोरिंग।
- रिटेल: इन्वेंटरी मैनेजमेंट, कस्टमर चर्न प्रेडिक्शन।
डीप लर्निंग के उदाहरण:
- कंप्यूटर विज़न:
- Google Photos: फेसेस और ऑब्जेक्ट्स को ऑटोमेटिकली रेकग्नाइज़ करना।
- मेडिकल इमेजिंग: MRI स्कैन्स में ट्यूमर्स की पहचान।
- नैचुरल लैंग्वेज प्रोसेसिंग (NLP):
- ChatGPT: ह्यूमन-लाइक टेक्स्ट जनरेशन।
- रियल-टाइम ट्रांसलेशन (Google Translate)।
- ऑटोनॉमस सिस्टम्स:
- ड्रोनज़: ऑब्स्टेकल अवॉइडेंस और रूट ऑप्टिमाइजेशन।
कब चुनें मशीन लर्निंग और कब डीप लर्निंग?
मशीन लर्निंग का उपयोग करें जब:
- आपके पास लिमिटेड डेटा है।
- प्रॉब्लम का स्कोप सीमित है (जैसे कस्टमर सेगमेंटेशन)।
- मॉडल इंटरप्रेटेबिलिटी जरूरी है (जैसे बैंकिंग, हेल्थकेयर)।
- कम्प्यूटेशनल रिसोर्सेज कम हैं।
डीप लर्निंग का उपयोग करें जब:
- डेटा बहुत बड़ा और अनस्ट्रक्चर्ड है (जैसे सोशल मीडिया पोस्ट्स, सैटेलाइट इमेजेस)।
- टास्क हाईली कॉम्प्लेक्स है (जैसे रियल-टाइम स्पीच रिकॉग्निशन)।
- हाई-परफॉर्मेंस हार्डवेयर (GPUs) उपलब्ध है।
- ब्लैक बॉक्स नेचर को मैनेज किया जा सकता है।
ML और DL का फ्यूचर: ट्रेंड्स और अपॉर्चुनिटीज़
- AutoML: मशीन लर्निंग को ऑटोमेट करने की टेक्नोलॉजी, जहां मॉडल्स ऑटोमेटिकली सेलेक्ट और ट्यून होते हैं।
- Edge AI: DL मॉडल्स को स्मार्टफोन्स और IoT डिवाइसेज पर डिप्लॉय करना (जैसे रियल-टाइम फेस अनलॉक)।
- Explainable AI (XAI): DL मॉडल्स की ट्रांसपेरेंसी बढ़ाने के प्रयास।
निष्कर्ष
मशीन लर्निंग और डीप लर्निंग दोनों ही AI की दुनिया में रेवोल्यूशनरी टेक्नोलॉजीज़ हैं, लेकिन इनका उपयोग केस-बाय-केस बेसिस पर डिपेंड करता है। ML अपनी सिंप्लिसिटी और इंटरप्रेटेबिलिटी के लिए जाना जाता है, जबकि DL अनस्ट्रक्चर्ड डेटा और कॉम्प्लेक्स टास्क में अनमैच्ड परफॉर्मेंस देता है। दोनों का सही समझ और एप्लीकेशन, बिजनेसेस और रिसर्चर्स को नेक्स्ट-लेवल इनोवेशन की ओर ले जा सकता है।
FAQs: मशीन लर्निंग (ML) और डीप लर्निंग(DL) के बारे में अक्सर पूछे जाने वाले प्रश्न
क्या डीप लर्निंग (DL), मशीन लर्निंग (ML) से हमेशा बेहतर होती है?
Answer:
नहीं! DL का उपयोग केवल specific scenarios में ही बेहतर है, जैसे:
जब unstructured data (इमेजेस, वीडियो, टेक्स्ट) बहुत बड़ी मात्रा में उपलब्ध हो।
Task highly complex हो, जैसे real-time object detection या natural language understanding।
ML, structured data (जैसे Excel sheets) और medium-sized datasets पर अधिक efficient और interpretable है। उदाहरण: बैंक loan approval systems में ML models को prioritize किया जाता है क्योंकि उनके निर्णयों को समझना आसान होता है।
क्या मैं छोटे डेटासेट पर डीप लर्निंग मॉडल्स ट्रेन कर सकता हूँ?
Answer:
Technically हाँ, लेकिन यह recommended नहीं है। DL models को high accuracy के लिए लाखों डेटा पॉइंट्स की आवश्यकता होती है। छोटे डेटासेट (कुछ हज़ार samples) पर DL models overfit हो जाते हैं (यानी training data को रट लेते हैं, real-world performance खराब होती है)। ऐसे cases में traditional ML algorithms (जैसे Random Forest, SVM) बेहतर perform करते हैं।
न्यूरल नेटवर्क्स के बिना क्या डीप लर्निंग संभव है?
Answer:
नहीं! डीप लर्निंग की पूरी concept ही Artificial Neural Networks (ANNs) पर आधारित है। ये multi-layered networks (input layer, hidden layers, output layer) डेटा से hierarchical features स्वयं सीखते हैं। बिना न्यूरल नेटवर्क्स के, आप DL का उपयोग नहीं कर सकते। हालांकि, ML में न्यूरल नेटवर्क्स का उपयोग optional है (जैसे simple ANNs), लेकिन वे “deep” नहीं माने जाते।